


New Sep 2020: in Proceedings of the National Academy of Sciences,
we update the methods and investigate the causal role of units.
See the new github repo
for updated code and methods.
Also see GAN Dissection, which extends these ideas to generative networks in some exciting ways.
house |
dog |
train |
plant |
airplane |
|
|---|---|---|---|---|---|
|
res5c unit 1410
IoU=0.142

|
res5c unit 1573
IoU=0.216

|
res5c unit 924
IoU=0.293

|
res5c unit 264
IoU=0.126

|
res5c unit 1243
IoU=0.172

|
|
|
res5c unit 301
IoU=0.087

|
res5c unit 1718
IoU=0.193

|
res5c unit 2001
IoU=0.255

|
res5c unit 766
IoU=0.092

|
res5c unit 1379
IoU=0.156

|
|
|
inception_4e unit 789
IoU=0.137

|
inception_4e unit 750
IoU=0.203

|
inception_5b unit 626
IoU=0.145

|
inception_4e unit 56
IoU=0.139

|
inception_4e unit 92
IoU=0.164

|
|
|
inception_4e unit 175
IoU=0.115

|
inception_5b unit 437
IoU=0.108

|
inception_5b unit 415
IoU=0.143

|
inception_4e unit 714
IoU=0.105

|
inception_4e unit 759
IoU=0.144

|
|
|
conv5_3 unit 243
IoU=0.070

|
conv5_3 unit 142
IoU=0.205

|
conv5_3 unit 463
IoU=0.126

|
conv5_3 unit 85
IoU=0.086

|
conv5_3 unit 151
IoU=0.150

|
|
|
conv5_3 unit 102
IoU=0.070

|
conv5_3 unit 491
IoU=0.112

|
conv5_3 unit 402
IoU=0.058

|
conv4_3 unit 336
IoU=0.068

|
conv5_3 unit 204
IoU=0.077

|
Selected units are shown from three state-of-the-art network architectures when trained to classify images of places (places-365). Many individual units respond to specific high-level concepts (object segmentations) that are not directly represented in the training set (scene classifications).
Why we study interpretable units
Interpretable units are interesting because they hint that deep networks may not be completely opaque black boxes.
However, the observations of interpretability up to now are
just a hint: there is not yet a complete understanding of
whether or how interpretable units are evidence of a so-called
distentangled representation.




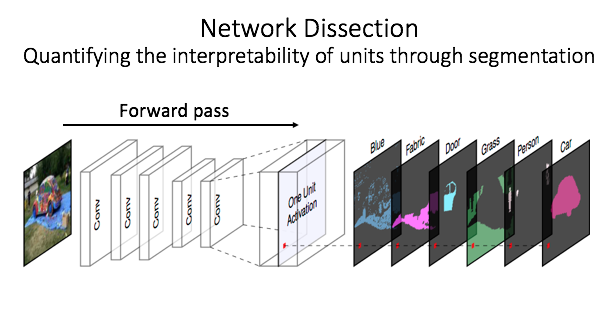
What is Network Dissection?
Our paper investigates three questions:
- What is a disentangled representation, and how can its factors be quantified and detected?
- Do interpretable hidden units reflect a special alignment of feature space, or are interpretations a chimera?
- What conditions in state-of-the-art training lead to representations with greater or lesser entanglement?
Network Dissection
is our method for quantifying interpretability of
individual units in a deep CNN (i.e., our answer to question #1).
It works by measuring the alignment between
unit response and a set of concepts drawn from a broad and dense
segmentation data set called Broden.


Are interpretations a chimera?
Network dissection shows that interpretable concepts are unusual
orientations of representation space. Their emergence is evidence
that the network is decomposing intermediate concepts,
answering question #2.

What affects interpretability?
This brings us to question #3: what conditions lead to higher or lower levels of interpretability?

")
We find that interpretabile units are found in representations of the major architectures for vision, and interpretable units also emerge under different training conditions including (to lesser degree) self-supervised tasks.
The code you find here will let you reproduce our interpretability benchmarks, and will allow you measure and find ways to improve interpretability in your own deep CNNs.
Videos
Network Dissection also allows us to understand how emergent concepts appear when training a model: in particular, it can quantify the change of representations under fine-tuning.
Network Dissection Results
Baseline AlexNet Models
Deep Architectures
Varied Training Conditions
Changes of Representation Basis
Self-Supervised Models
Training Iterations
Related Work
Several lines of research have shown ways to analyze internal representations of deep neural networks.
Generative Visualizations of Individual Units
 A. Mahendran and A. Vedaldi. Understanding deep image representations
by inverting them. Computer Vision and Pattern Recognition (CVPR), 2015.
A. Mahendran and A. Vedaldi. Understanding deep image representations
by inverting them. Computer Vision and Pattern Recognition (CVPR), 2015.
Comment: Computing visualizations of internal representations as function inversions that generate results with natural-image statistics.
 A. Nguyen, A. Dosovitskiy, J. Yosinski, T. Brox, J. Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. Advances in Neural Information Processing Systems (NIPS), 2016.
A. Nguyen, A. Dosovitskiy, J. Yosinski, T. Brox, J. Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. Advances in Neural Information Processing Systems (NIPS), 2016.
Comment: Generating remarkably realistic image visualizations for units in representations using techniques from generative adversarial networks.
 K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional
networks: Visualising image classification models and saliency
maps. International Conference on Learning Representations Workshop,
2014.
K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional
networks: Visualising image classification models and saliency
maps. International Conference on Learning Representations Workshop,
2014.
Comment: Applying gradient descent to generate visualizations of units in convolutional neural networks.
 J. Springenberg, A. Dosovitskiy, T.Brox, M. Riedmiller. Striving for simplicity: The all convolutional net. International Conference on Learning Representations Workshop, 2015.
J. Springenberg, A. Dosovitskiy, T.Brox, M. Riedmiller. Striving for simplicity: The all convolutional net. International Conference on Learning Representations Workshop, 2015.
Comment: Defines guided backpropagation to visualize features of convolutional neural networks.
Salience-based Visualizations of Individual Units
 M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional
networks. European Conference on Computer Vision (ECCV), 2014.
M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional
networks. European Conference on Computer Vision (ECCV), 2014.
Comment: Introduces deconvolutional networks for generating visualizations, and shows how visualizations can motivate improvements in a network architecture.
 B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba.
Object Detectors Emerge in Deep Scene CNNs.
International Conference on Learning Representations (ICLR), 2015.
[PDF][Code]
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba.
Object Detectors Emerge in Deep Scene CNNs.
International Conference on Learning Representations (ICLR), 2015.
[PDF][Code]
Comment: In this work we used AMT workers to observe emergent interpretable object detectors inside the CNN trained for classifying scenes.
 B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba.
Learning Deep Features for Discriminative Localization.
Computer Vision and Pattern Recognition (CVPR), 2016.
[PDF]
[Webpage][Code]
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba.
Learning Deep Features for Discriminative Localization.
Computer Vision and Pattern Recognition (CVPR), 2016.
[PDF]
[Webpage][Code]
Comment: In this work we used class activation mapping to reveal salience maps for individual units.
Visualizing Representations as a Whole
 L.V. Maaten, G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research (JMLR), 2008.
[PDF]
L.V. Maaten, G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research (JMLR), 2008.
[PDF]
Comment: T-SNE is a powerful dimensionality reduction technique that can be used for visualizing a representation space.
 J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, H. Lipson. Understanding neural networks through deep visualization. International Conference on Machine Learning Deep Learning Workshop, 2015.
J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, H. Lipson. Understanding neural networks through deep visualization. International Conference on Machine Learning Deep Learning Workshop, 2015.
Comment: Describes an interactive interface for exploring a representation by visualizaing all its units at once.
Quantifying Internal Representations
 P. Agrawal, R. Girshick, and J. Malik. Analyzing the performance of
multilayer neural networks for object recognition.
European Conference on Computer Vision (ECCV), 2014.
P. Agrawal, R. Girshick, and J. Malik. Analyzing the performance of
multilayer neural networks for object recognition.
European Conference on Computer Vision (ECCV), 2014.
Comment: Investigates the "grandmother neuron" hypothesis inside convolutional networks.
 A. S. Razavian, H. Azizpour, J. Sullivan, and S. Carlsson. CNN
features off-the-shelf: an astounding baseline for recognition.
arXiv:1403.6382, 2014.
A. S. Razavian, H. Azizpour, J. Sullivan, and S. Carlsson. CNN
features off-the-shelf: an astounding baseline for recognition.
arXiv:1403.6382, 2014.
Comment: Quantifies the power of hidden representations by measuring their ability to be applied in solving problems different from the original training goal.
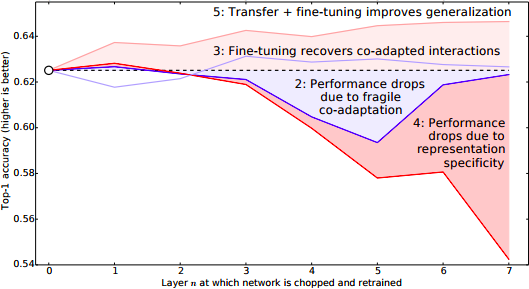 J. Yosinski, J. Clune, Y. Bengio, and H. Lipson. How transferable are
features in deep neural networks? Advances in Neural Information
Processing Systems (NIPS), 2014.
J. Yosinski, J. Clune, Y. Bengio, and H. Lipson. How transferable are
features in deep neural networks? Advances in Neural Information
Processing Systems (NIPS), 2014.
Comment: Quantifies hidden representations by measuring the transferability of features by training subsets of layers under varied conditions.
Media
 MIT researchers can now track AI's decisions back to single neurons. The ability to measure bias in neural networks could be critical in fields like healthcare, where bias inherent in an algorithm's training data could be carried into treatment, or in determining why self-driving cars make certain decisions on the road for a safer vehicle.
MIT researchers can now track AI's decisions back to single neurons. The ability to measure bias in neural networks could be critical in fields like healthcare, where bias inherent in an algorithm's training data could be carried into treatment, or in determining why self-driving cars make certain decisions on the road for a safer vehicle.
 MIT CSAIL research offers a fully automated way to peer inside neural nets. Already, the research is providing interesting insight into how neural nets operate, for example showing that a network trained to add color to black and white images ends up concentrating a significant portion of its nodes to identifying textures in the pictures.
MIT CSAIL research offers a fully automated way to peer inside neural nets. Already, the research is providing interesting insight into how neural nets operate, for example showing that a network trained to add color to black and white images ends up concentrating a significant portion of its nodes to identifying textures in the pictures.
 Peering into neural networks. Because their system could frequently identify labels that corresponded to the precise pixel clusters that provoked a strong response from a given node, it could characterize the node's behavior with great specificity.... One of the researchers' experiments could conceivably shed light on a vexed question in neuroscience.
Peering into neural networks. Because their system could frequently identify labels that corresponded to the precise pixel clusters that provoked a strong response from a given node, it could characterize the node's behavior with great specificity.... One of the researchers' experiments could conceivably shed light on a vexed question in neuroscience.
Citation
Bibilographic information for this work:
Citation
(*first two authors contributed equally.)
Bibtex
@inproceedings{netdissect2017,
title={Network Dissection: Quantifying Interpretability of Deep Visual Representations},
author={Bau, David and Zhou, Bolei and Khosla, Aditya and Oliva, Aude and Torralba, Antonio},
booktitle={Computer Vision and Pattern Recognition},
year={2017}
}
Also Cite
We more recently published a journal article in the Proceedings of the National Academy of Sciences:
Citation
Bibtex
@article{bau2020units,
author = {Bau, David and Zhu, Jun-Yan and Strobelt, Hendrik and Lapedriza, Agata and Zhou, Bolei and Torralba, Antonio},
title = {Understanding the role of individual units in a deep neural network},
elocation-id = {201907375},
year = {2020},
doi = {10.1073/pnas.1907375117},
publisher = {National Academy of Sciences},
issn = {0027-8424},
URL = {https://www.pnas.org/content/early/2020/08/31/1907375117},
journal = {Proceedings of the National Academy of Sciences}
}
Acknowledgement: This work was partly supported by the National Science Foundation under Grants No. 1524817 to A.T., and No. 1532591 to A.T. and A.O.; the Vannevar Bush Faculty Fellowship program sponsored by the Basic Research Office of the Assistant Secretary of Defense for Research and Engineering and funded by the Office of Naval Research through grant N00014-16-1-3116 to A.O.; the MIT Big Data Initiative at CSAIL, the Toyota Research Institute MIT CSAIL Joint Research Center, Google and Amazon Awards, and a hardware donation from NVIDIA Corporation. B.Z. is supported by a Facebook Fellowship.